概览
1.安装scala
2.单机版的安装部署
3.spark集群的安装部署
4.基于Zookeeper的Spark高可用集群
准备
CentOS7
scala-2.10.5
spark-2.1.1-bin-hadoop2.7
hadoop高可用集群(或普通集群)
工具:VMware12 Xshell5 Xftp5
1.安装scala
因为spark需要scala的环境,所以需要先安装scala
启动虚拟机,利用Xshell连接,使操作更加方便,然后使用Xftp连接以便上传文件
首先在/usr路径下创建一个scala文件夹当作安装目录以及安装包的上传路径
1 | [root@master ~]# cd /usr/ |
利用Xftp上传scala的压缩包到此路径下
解压
1 | [root@master scala]# tar -zxf scala-2.10.5.tgz |
配置环境变量
1 | [root@master scala]# vim /etc/profile |
在最后添加上两行
1 | #scala的安装目录 |
esc+:wq保存退出
刷新环境变量
1 | [root@master scala]# source /etc/profile |
验证是否安装成功
1 | [root@master scala]# scala -version |
2.单机版的安装部署
在/usr下创建一个spark文件夹当作安装目录和安装包上传路径
1 | [root@master scala]# cd .. |
还是通过Xftp将spark安装包上传到此路径下
解压
1 | [root@master spark]# tar -zxf spark-2.1.1-bin-hadoop2.7.tgz |
配置环境变量
1 | [root@master spark]# vim /etc/profile |
在最后添加两行
1 | export SPARK_HOME=/usr/spark/spark-2.1.1-bin-hadoop2.7 |
保存退出刷新环境变量
1 | [root@master spark]# source /etc/profile |
测试
运行一个简单的spark程序
spark-shell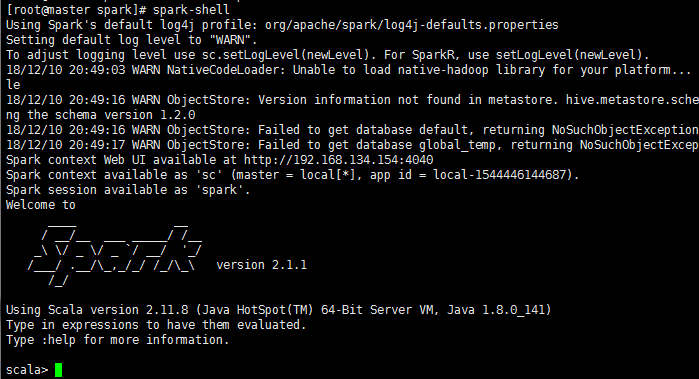
可以在/tmp文件夹下创建一个测试文件
先复制个Xshell窗口
在新的窗口操作
1 | [root@master ~]# cd /tmp/ |
我们在a.log中创建一些假数据
1 | hello world |
然后在原来的窗口操作
1 | scala> sc.textFile("/tmp/a.log").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println) |
会出现如上的结果
这说明我们的单机版spark安装成功了
退出spark操作页面
1 | scala> :q |
接下来会在单机版的基础上安装spark集群
3.spark集群的安装部署
首先我们需要在master主机上配置好单机版spark
集群的搭建需要我们预先搭建好hadoop高可用集群(或普通集群)才行
集群规划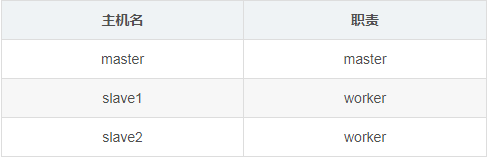
首先我们在已经安装好单机spark的master上继续配置
修改spark-env .sh
记住先停止单机版的spark
查看jps进程,如果还在运行就强制杀死进程
修改spark-env.sh文件
1 | [root@master spark]# cd /usr/spark/spark-2.1.1-bin-hadoop2.7/conf/ |
我们会发现没有这个文件,但是却有一个spark-env.sh.template文件,利用这个模版复制出来一个spark-env .sh
1 | [root@master conf]# cp spark-env.sh.template spark-env.sh |
修改
1 | [root@master conf]# vim spark-env.sh |
在最后添加这几行
1 | #Java的安装路径 |
保存退出
配置slaves文件
依然拷贝出来一个slaves配置文件
1 | [root@master conf]# ls |
修改
1 | [root@master conf]# vim slaves |
配置成如下
修改启动文件
为了避免和hadoop中的start/stop-all.sh脚本发生冲突,将spark/sbin/的start/stop-all.sh重命名
1 | [root@master conf]# cd /usr/spark/spark-2.1.1-bin-hadoop2.7/sbin/ |
发送
将配置好的scala和spark发送给其他主机
1 | #发送scala |
分别在slave1和slave2上刷新环境变量
1 | [root@slave1 ~]# source /etc/profile |
再安装上面验证scala是否成功安装
启动
①启动Zookeeper集群
分别在三台主机上启动
1 | zkServer.sh start |
启动之后查看状态
1 | zkServer.sh status |
如果是leader或者follower便启动成功
②启动hadoop集群
在master主节点上启动hadoop集群
1 | start-all.sh |
查看jps
master
1 | [root@master usr]# jps |
slave11
2
3
4
5
6
7
8[root@slave1 ~]# jps
2338 DataNode
2626 NodeManager
2515 DFSZKFailoverController
2771 Jps
2436 JournalNode
2268 NameNode
2207 QuorumPeerMain
slave2
1 | [root@slave2 ~]# jps |
如果少启动尝试各自启动其功能,例如ResourceManager没启动可以在slave2上使用start-yarn.sh启动,或者重新启动所有服务
③启动spark集群
在职责为master的主机上启动
start-spark-all.sh
如果启动出错请仔细查看异常,检查配置文件是否配置出错
测试
我们将之前的在tmp上创建的a.log上传到hdfs上
1 | [root@master usr]# hadoop fs -put /tmp/a.log / |
然后在master上启动spark-shell
1 | [root@master usr]# spark-shell |
如果启动出错请仔细查看异常,检查配置文件是否配置出错
然后输入scala命令
1 | #这里的master:9000是hadoop中active的namenode节点 |
如果得出以上结果便正面spark集群正常
你可以访问master的IP地址:8080查看spark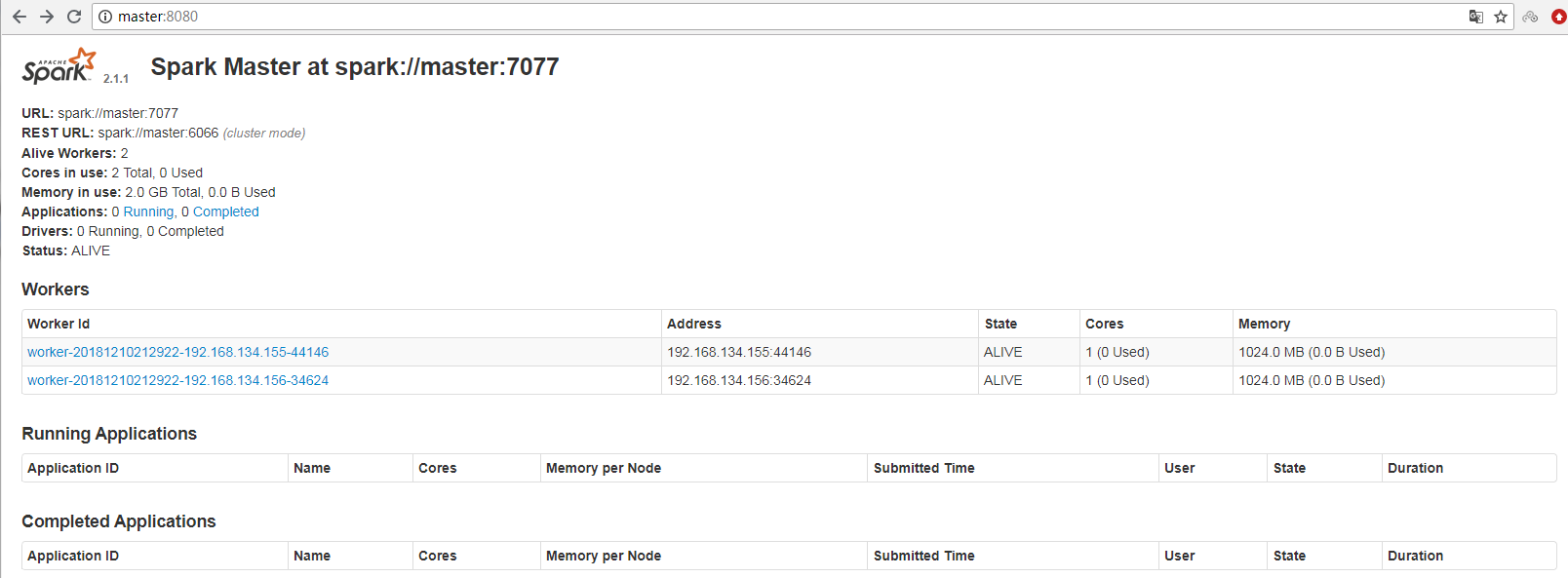
4.基于Zookeeper的Spark高可用集群
spark高可用是基于普通集群版的基础上搭建的
①修改spark-env. sh
注释掉spark-env.sh中的两行
1 | [root@master spark]# cd /usr/spark/spark-2.1.1-bin-hadoop2.7/conf/ |
将
1 | #export SPARK_MASTER_IP=master |
注释掉
在最后添加一行
1 | export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark" |
解释
spark.deploy.recoveryMode设置成 ZOOKEEPER
spark.deploy.zookeeper.url ZooKeeper URL
spark.deploy.zookeeper.dir ZooKeeper 保存恢复状态的目录,缺省为 /spark
②重启集群
首先确保Zookeeper和hadoop集群的启动,防火墙的关闭
在任何一台spark节点上启动start-spark-all. sh
手动在集群中其他从节点上再启动master进程:在slave1上启动sbin/start-master.sh
③测试
通过浏览器方法 master:8080 /slave1:8080–>Status: STANDBY Status: ALIVE
验证HA高可用,只需要手动停掉master上spark进程Master,等一会slave1上的进程Master状态会从STANDBY变成ALIVE