概览
1.Flume流程简介
2.规划
3.配置
4.启动测试
5.注意
准备
操作系统:CentOS 7
搭建好hadoop集群
Flume版本:1.8.0
jdk版本:1.8.0_141
工具:Xshell 5,Xftp 5,VMware Workstation Pro
1.Flume流程简介
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合,最后存储到一个中心化数据存储系统中,方便进行数据分析。事实上flume也可以收集其他信息,不仅限于日志。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。相比较而言,flume NG更简单更易于管理操作。
Flume OG:Flume original generation 即Flume 0.9.x版本
Flume NG:Flume next generation 即Flume 1.x版本。
Flume NG用户参考手册:http://flume.apache.org/FlumeUserGuide.html#
简单比较一下两者的区别:
OG有三个组件agent、collector、master,agent主要负责收集各个日志服务器上的日志,将日志聚合到collector,可设置多个collector,master主要负责管理agent和collector,最后由collector把收集的日志写的HDFS中,当然也可以写到本地、给storm、给Hbase。
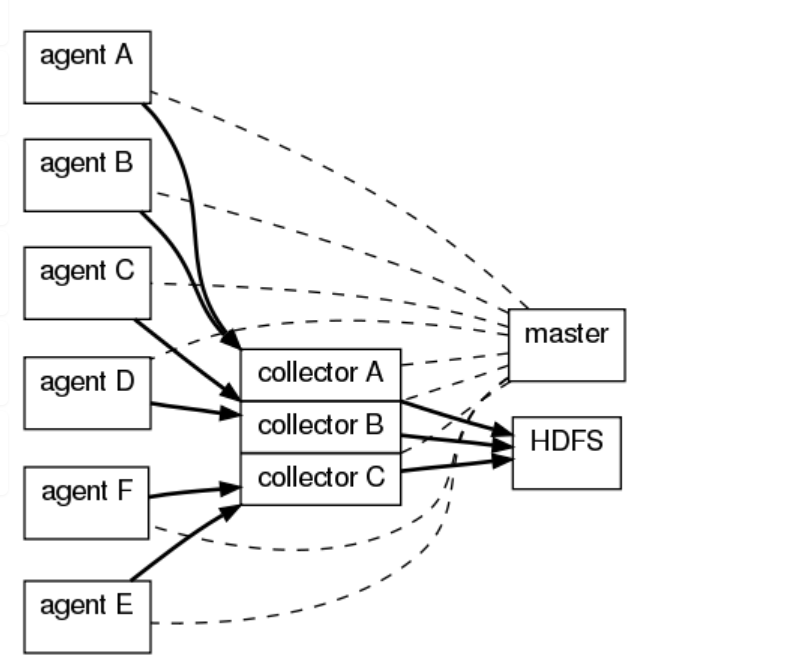
NG最大的改动就是不再有分工角色设置,所有的都是agent,可以彼此之间相连,多个agent连到一个agent,此agent也就相当于collector了,NG也支持负载均衡.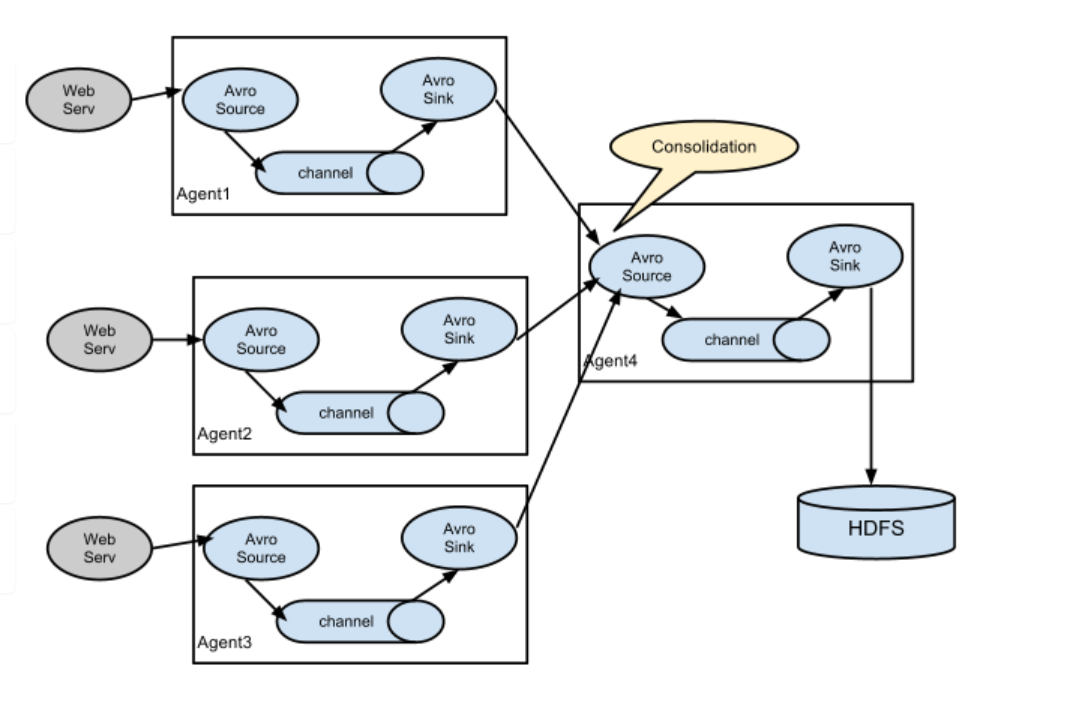
2.规划
三台主机的主机名分别为master,slave1,slave2(防火墙已关闭)
由slave1和slave2收集日志信息,传给master,再由master上传到hdfs上
3.配置
3.1上传解压
在slave1上的usr文件夹下新建个flume文件夹,用作安装路径
1 | [root@slave1 usr]# mkdir flume |
利用Xftp工具将flume压缩包上传到usr/flume文件夹下,解压
1 | [root@slave1 flume]# ls |
3.2 .配置flume-env.sh文件
1 | # 进入到conf文件夹下 |
将java的安装路径修改为自己的
我的是/usr/java/jdk1.8.0_141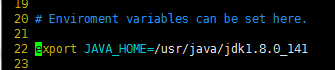
3.3 配置slave.conf文件
在conf下创建一个新的slave.conf文件
1 | #创建 |
写入配置内容
1 | # 主要作用是监听目录中的新增数据,采集到数据之后,输出到avro (输出到agent) |
保存退出
3.4 将flume发送到其他主机
1 | [root@slave1 conf]# scp -r /usr/flume/ root@slave2:/usr/ |
3.5 修改master中flume的配置
在master的flume的conf文件夹下创建一个master.conf文件
1 | [root@master conf]# vim master.conf |
写入配置信息
1 | # 获取slave1,2上的数据,聚合起来,传到hdfs上面 |
保存退出
4.启动测试
确认防火墙关闭
首先启动Zookeeper和hadoop集群,参考hadoop集群搭建中的启动
然后先启动master上的flume(如果先启动slave上的会导致拒绝连接)
在apache-flume-1.8.0-bin目录下启动(因为没有配置环境变量)
1 | [root@master apache-flume-1.8.0-bin]# bin/flume-ng agent -n a1 -c conf -f conf/master.conf -Dflume.root.logger=INFO,console |
如此便是启动成功
如果想后台启动(这样可以不用另开窗口操作)
1 | # 命令后加& |
再启动slave1,2上的flume
首先在slave1,2的根目录创建logs目录
1 | [root@slave1 apache-flume-1.8.0-bin]# cd / |
不然会报错
1 | [ERROR - org.apache.flume.lifecycle.LifecycleSupervisor$MonitorRunnable.run(LifecycleSupervisor.java:251)] Unable to start EventDrivenSourceRunner: { source:Spool Directory source r1: { spoolDir: /logs } } - Exception follows. |
1 | #slave1 |
测试
启动成功后(如果没有后台启动另开个窗口继续下面操作)
在slave1的usr/tmp文件夹下新建个test文件
1 | [root@slave1 tmp]# vim test |
随便写入一些内容
1 | helloworld |
保存退出
将其复制到logs文件夹下
1 | [root@slave1 tmp]# cp test /logs/ |
查看master
登录http://(hadoop中active状态的namenode节点IP):50070/explorer.html#

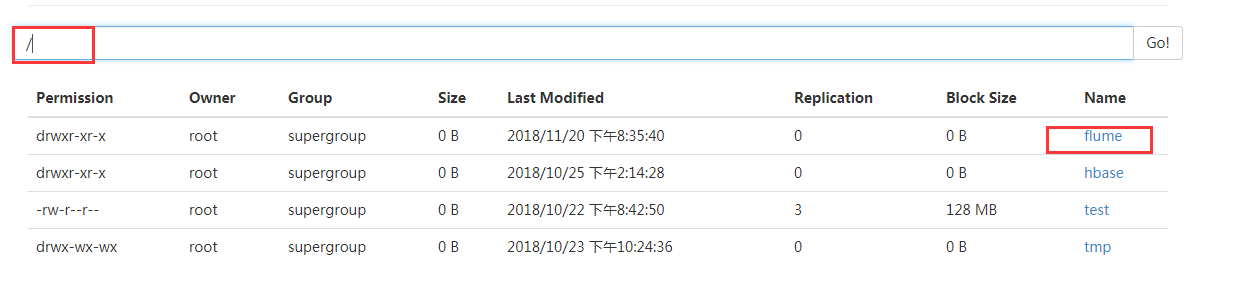

如此便是flume多节点集群搭建完成
5.注意
登录查看需要是active的节点地址,具体参考hadoop集群搭建中的测试
在启动slave上的flume前要先建立logs文件夹,也就是flume安装路径/conf下的slave.conf文件中的