概览
1.MapReduce处理手机上网记录
2.Partitioner分区
上次说过了关于MapReduce的执行流程和原理,下面来说下分区和简单示例
1.MapReduce处理手机上网记录
首先我们需要先模拟一个通话记录文件
在Windows的桌面建个tel.log的文件,里面模拟一些通话记录信息
1 | 1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 |
这些字段代表的是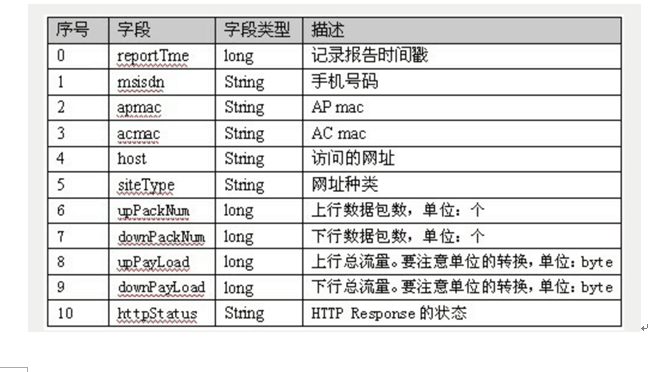
首先我们需要将部分字段提取出来,以便之后进行分析
在主机master上启动hadoop集群,hadoop集群版的搭建可以参照简单的hadoop集群搭建
1 | start-all.sh |
验证是否启动成功
然后将tel.log文件利用Xftp传输到虚拟机中的/usr/tmp下cd /usr/tmp/
然后上传到hdfs
1 | #上传 |
然后在eclipse上新建java项目,并在项目下建个lib文件夹,然后将jar包放到lib中导入项目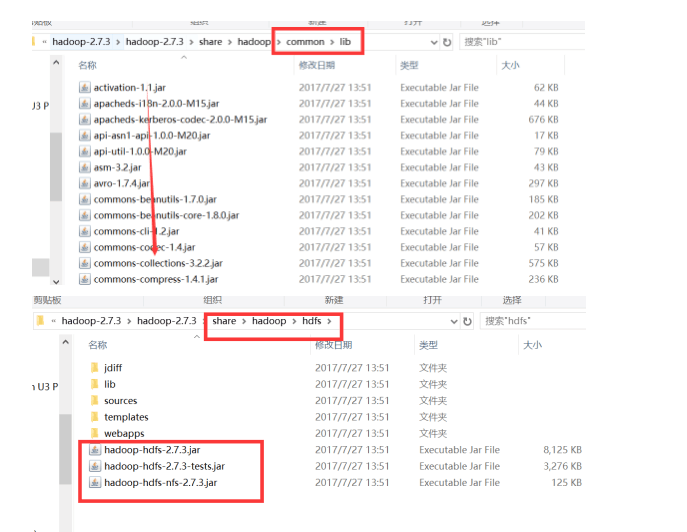
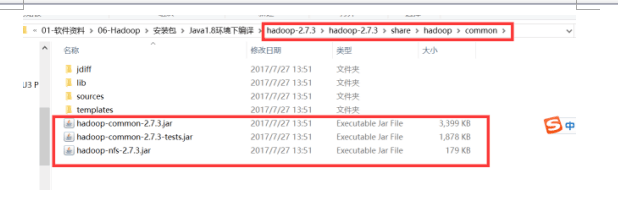
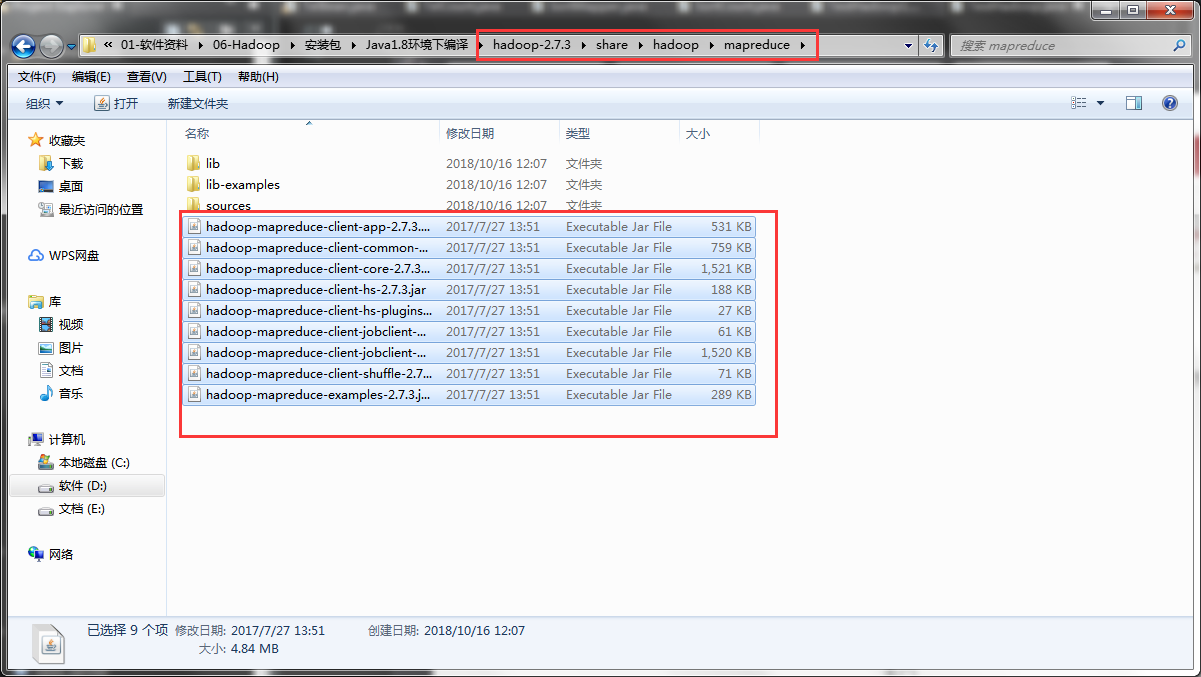
然后创建包,创建一个telBean实体类,这次我们分析的是
手机号和其对应的上行流量,下行流量和总流量
所以将其封装成实体类
1 | package com.hd.entity; |
在mr包下创建个TelMapper类继承Mapper
首先分析一下,我们要传入的第一个需要Map处理的<k1,v1>是long类型(电话号码)和String(Text)类型(与之对应的一行记录),而从Map处理过的<k2,v2>是String类型(电话号码)和TelBean对象(将我们需要的字段封装成对象)
1 | package com.hd.hadoop.mr; |
然后创建个TelReducer类继承Reducer
分析一下,这里传入的<k2,v2>是String(Text)类型和TelBean类型,而我们处理过输出的<k3,v3>也是相同类型,这里要记得将TelBean的toString方法重写,不然输出的是对象地址
1 | package com.hd.hadoop.mr; |
最后我们创建个主方法TelCount类
1 | package com.zy.hadoop.mr1; |
最后将其打成Jar包,主方法选择TelCount,然后上传到虚拟机/usr/tmp下
然后执行jar包
1 | hadoop jar tel_1.jar /tel.log /tel1 |
等待执行成功后查看结果文件
1 | #结果如下 |
这说明执行成功了
2.Partitioner分区
什么是Partitioner?
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
我们还是处理手机的上网记录
在之前的mr包中见一个TCPartitioner类
我们将135和136开头的号码视为移动用户,处理结果放到一起(part-r-00000),另外的号码处理结果放到一起(part-r-00001)
1 | package com.hd.hadoop.mr; |
然后在TelCount添加几行代码
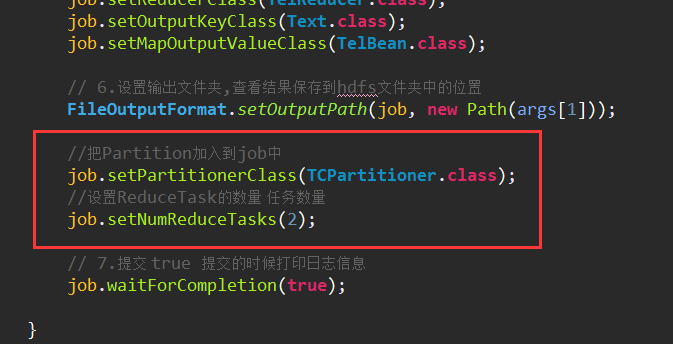
再将项目打成jar包放入到虚拟机/usr/tmp下,然后执行
1 | hadoop jar tel_2.jar /tel.log /tel2 |
等待执行完毕后查看结果
1 | #查看生成几个结果文件 |
这就是简单的分区操作
接下来还有如何将分析的结果进行排序操作