概览
1.MapReduce简介
2.MapReduce的执行流程
3.MapReduce的原理
4.测试MapReduce
5.Java代码实现
1.MapReduce简介
MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理。实现下面目标
★ 易于编程
★ 良好的扩展性
★ 高容错性
MapReduce有哪些角色?各自的作用是什么?
MapReduce由JobTracker和TaskTracker组成。JobTracker负责资源管理和作业控制,TaskTracker负责任务的运行。
2.MapReduce的执行流程
MapReduce程序执行流程
程序执行流程图如下: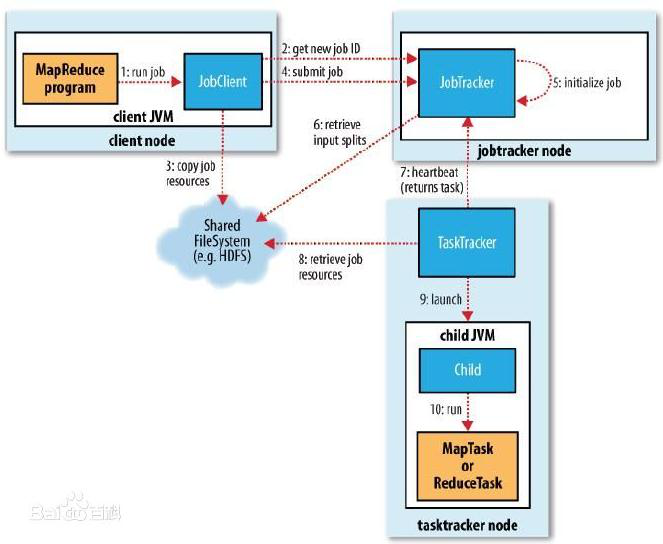
(1) 开发人员编写好MapReduce program,将程序打包运行。
(2) JobClient向JobTracker申请可用Job,JobTracker返回JobClient一个可用Job ID。
(3) JobClient得到Job ID后,将运行Job所需要的资源拷贝到共享文件系统HDFS中。
(4) 资源准备完备后,JobClient向JobTracker提交Job。
(5) JobTracker收到提交的Job后,初始化Job。
(6) 初始化完成后,JobTracker从HDFS中获取输入splits(作业可以该启动多少Mapper任务)。
(7) 与此同时,TaskTracker不断地向JobTracker汇报心跳信息,并且返回要执行的任务。
(8) TaskTracker得到JobTracker分配(尽量满足数据本地化)的任务后,向HDFS获取Job资源(若数据是本地的,不需拷贝数据)。
(9) 获取资源后,TaskTracker会开启JVM子进程运行任务。
注:
(3)中资源具体指什么?主要包含:
● 程序jar包、作业配置文件xml
● 输入划分信息,决定作业该启动多少个map任务
● 本地文件,包含依赖的第三方jar包(-libjars)、依赖的归档文件(-archives)和普通文件(-files),如果已经上传,则不需上传
3.MapReduce原理
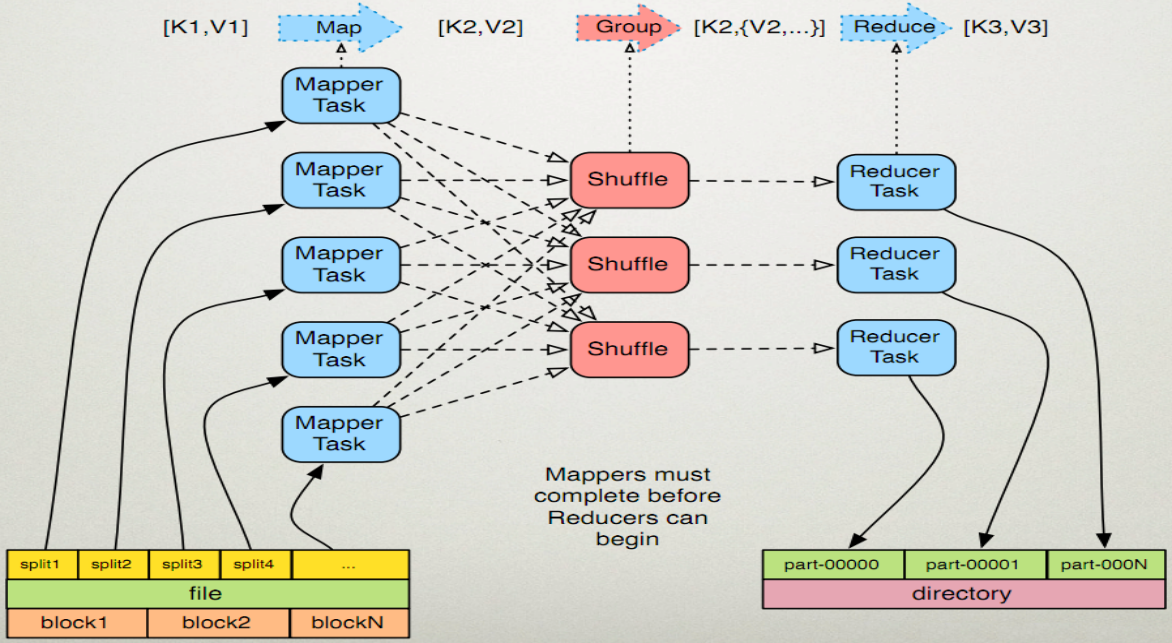
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。
<0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。
<hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:
<hello,1> <hello,1> <me,1> <you,1>
分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。(shuffle)详见《shuffle过程分析》
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑,
<hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
4.测试MapReduce
启动虚拟机利用Xshell工具连接
启动hadoop
1 | start-all.sh |
上传到hdfs上一个文件test1
文件test1的内容如下
1 | hello world |
进入/usr/hadoop/hadoop-2.7.3/share/hadoop/mapreduce下
1 | cd /usr/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/ |
有个 hadoop-mapreduce-examples-2.7.3.jar的jar包
为test1执行这个jar包
1 | hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /test1 /result |
等待执行,然后查看result文件内容
1 | #查看result文件夹 |
这个就是按照你所执行的文件,一次读取一行的内容,然后每行用空格分隔
如图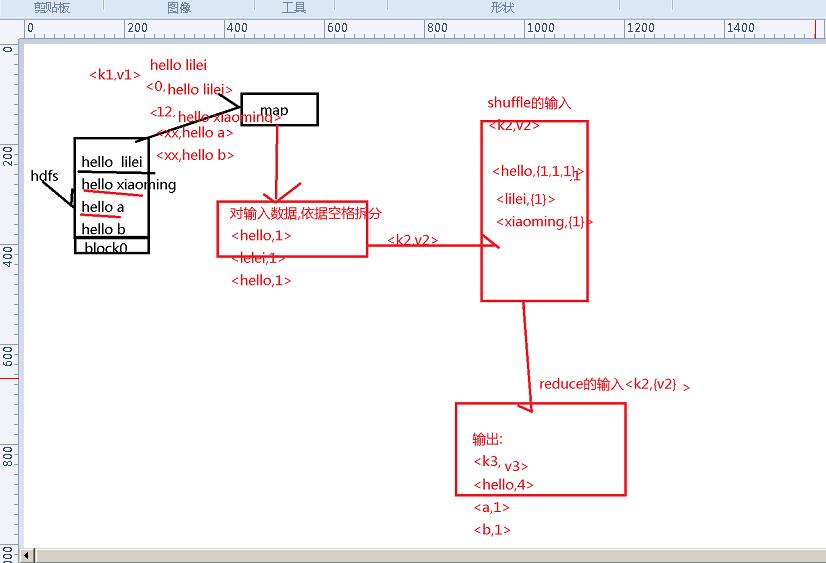
5.Java代码实现
首先eclipse建个Java项目,然后项目下建个lib文件夹放置jar包
将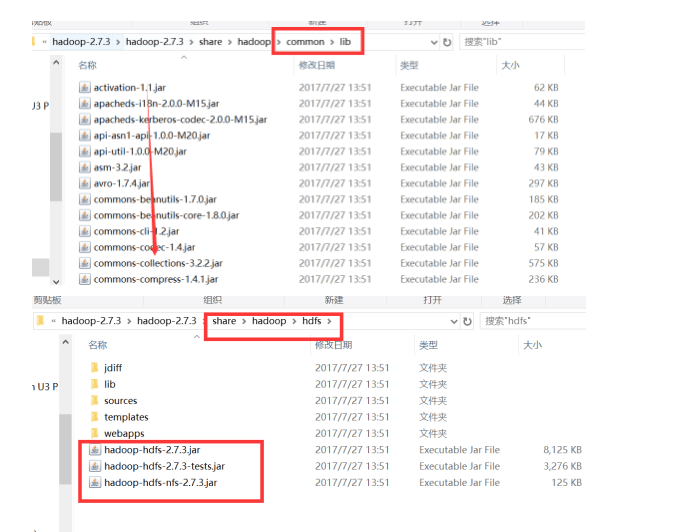
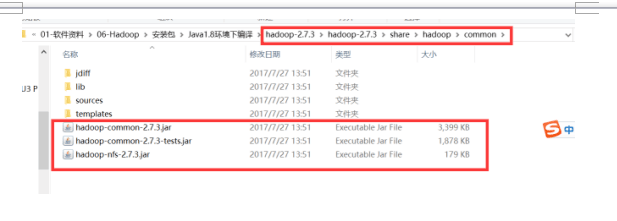
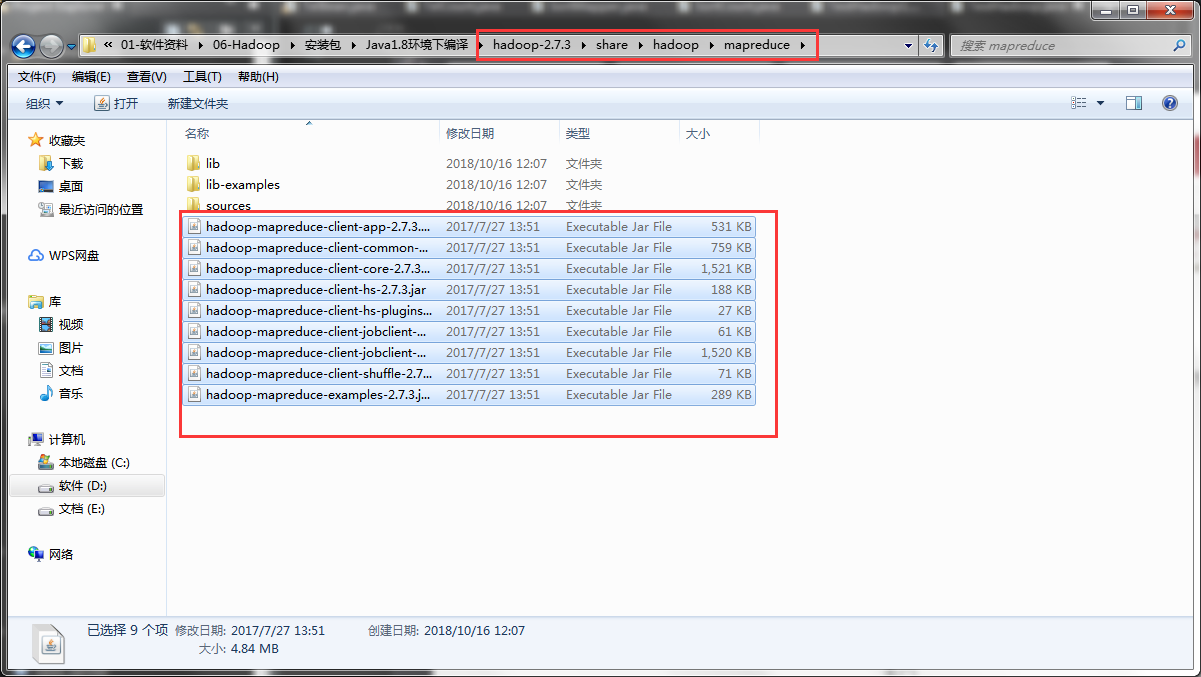
复制到lib下,然后add to Build Path
建立个mr包,在其中建立WCMapper,WCReducer,WordCount
WCMapper
1 | package com.hd.hadoop.mr; |
WCReducer
1 | package com.hd.hadoop.mr; |
WordCount
1 | package com.hd.hadoop.mr; |
然后打成jar包
项目右键export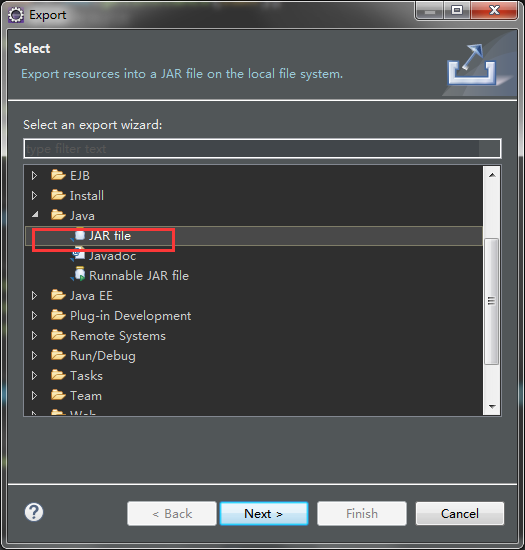
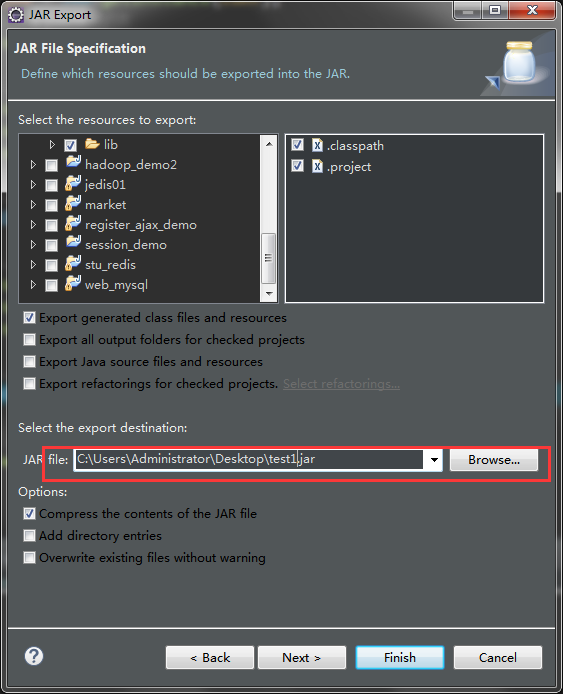
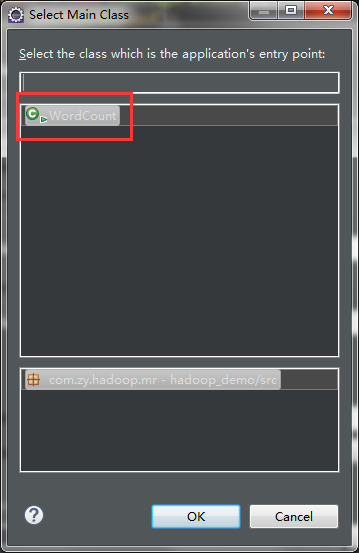
然后将打好的jar包利用Xftp工具放入到虚拟机master的/usr/tmp文件夹下cd /usr/tmp
然后执行1
hadoop jar test1.jar
等待执行完毕
查看
1 | [root@master tmp]# hadoop fs -ls /result1 |
这就是MapReduce的原理和执行流程
不清楚的话可以去多查看一些资料
接下来还会写一些别的示例还有Partitioner分区的用法