概览
1.规划
2.克隆虚拟机
3.在hosts文件修改ip映射
4.修改hadoop配置文件
5.更改slaves文件
6.集群版ssh免密钥登录
7.重新格式化namenode
8.启动hadoop并验证是否成功
9.若slave的datanode没有启动
上次说了Hadoop集群单机版的搭建,这次来依照单机版的基础搭建一个简单的集群版
1.规划
这次搭建的是一个主机和两个从机,也就是只有两个node节点,也可以让主机上有node节点,之后会说
|主机名|cluster规划 |
|–|–|
| master | namenode,secondarynamenode,ResourceManager |
| slave1 | Datanode, NodeManager |
| slave2 | Datanode, NodeManager |
首先克隆一台单机版虚拟机
2.克隆虚拟机
虚拟机右键–>管理–>克隆,选择创建完整克隆,
这里克隆几个要看你创建的集群规模,我便克隆三台,一台主机,两台从机.
然后启动虚拟机,改动静态ip
这个需要三台虚拟机都改动
还是到/etc/sysconfig/network-scripts文件夹下改动ifcfg-ens33文件
1 | vim /etc/sysconfig/network-scripts/ifcfg-ens33 |
前面配置单机版的时候,如果觉得vi的命令不好用,可以安装vim命令 yum -y install vim之后就可以使用vim命令了.比vi编辑命令更加清晰
改动如图:
将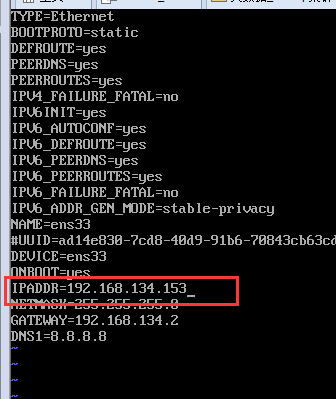
改为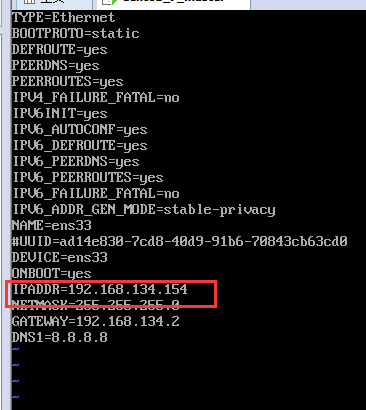
这个虚拟机的ip只要是你没有使用的即可
然后保存,重启服务
1 | systemctl restart network |
接下来使用Xshell工具分别连接三台虚拟机(没有的去官网下载,有免费版本),Xshell的优点在于你可以随意的复制粘贴命令语句
3.在hosts文件修改ip映射
找到到hosts文件进行编辑
1 | vim /etc/hosts |
写入三台主机的ip地址和主机名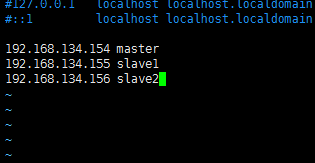
1 | 192.168.134.154 master |
这里改动过之后最好重启虚拟机reboot,让其生效,这样最后配置ssh免密钥登录时不会出现异常
4.修改hadoop配置文件
如果你的主机名还是单机版的.可以不用更改
然后进入到 /usr/hadoop/hadoop-2.7.3/etc/hadoop/下修改core-site.xml和yarn-site.xml , 三个虚拟机都要更改,也可以只修改一台之后发送
将之前的主机名改为现在的主机 master
如图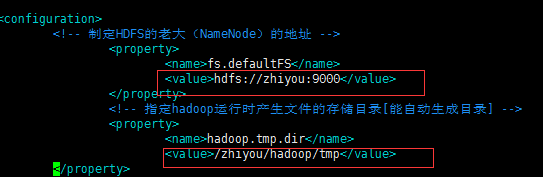
改为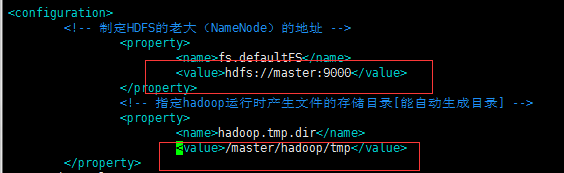
将yarn-site.xml内的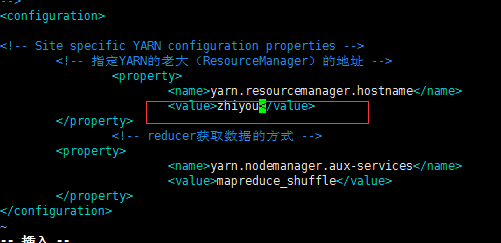
改为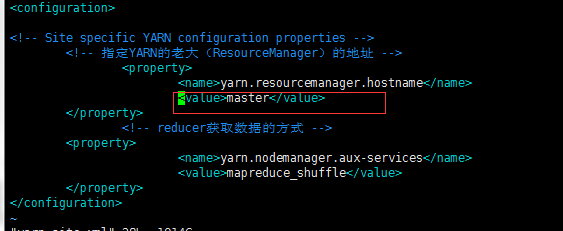
当然,如果你的主机名还是用的单机版的,那么上述两步可以不改
接下来更改slaves文件
5.更改slaves文件
还是在该文件夹下
更改slaves文件
三个虚拟机都需要更改(其实这些都可以在克隆前更改,再克隆,不过也可以配置好后再发送)1
vim slaves
改为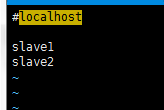
这里需要说明一下,如果你要主机也当作一个节点的话 , 那么在里面也要添加主机名称,这个文件就是告诉hadoop该启动谁的datanode
如果需要发送给另外主机的话就是
1 | #会直接覆盖掉之前的 |
之后最重要的是ssh免密登录的配置
6.集群版ssh免密钥登录
三台虚拟机都需要操作
进入到~/.ssh
#每台机器先使用ssh执行以下,以在主目录产生一个.ssh 文件夹
ssh master
创建 ,然后进入 cd ~/.ssh
1 |
|
如果more authorized_keys 查看如图
@后是你的主机名则表示正常,否则重新进行上几步进行覆写
然后分别把从机slave1和slave2的authorized_keys文件进行合并(最简单的方法是将其余三台slave主机的文件内容追加到master主机上)
1 | #将所有的authorized_keys文件进行合并(最简单的方法是将其余三台slave主机的文件内容追加到master主机上) |
然后分发主机上的密钥 authorized_keys
1 | #将master上的authorized_keys文件分发到其他主机上 |
7.重新格式化namenode
三台虚拟机都需要1
hadoop namenode -format
8.启动hadoop并验证是否成功
在主机master上直接启动start-all.sh从机会跟着启动
然后分别在主机从机上查看jps
应该与规划相同
|主机名|cluster规划 |
|–|–|
| master | namenode,secondarynamenode,ResourceManager |
| slave1 | Datanode, NodeManager |
| slave2 | Datanode, NodeManager |
9.若slave的datanode没有启动
如果发现从机的datanode没有启动
首先在主机master停止
stop-all.sh
然后进入到从机的/usr/local/hadoop/tmp/dfs/data
cd /usr/local/hadoop/tmp/dfs/data
也就是hdfs-site.xml文件中dfs.datanode.data.dir的路径,data的存放位置,将其中的current删除
rm -rf current/
然后重新初始化namenode 再重新启动hadoop即可
hadoop namenode -format
start-all.sh
然后在http://主机master的ip:50070和http://主机master的ip:8088分别查看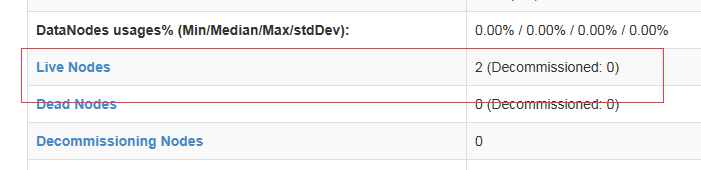
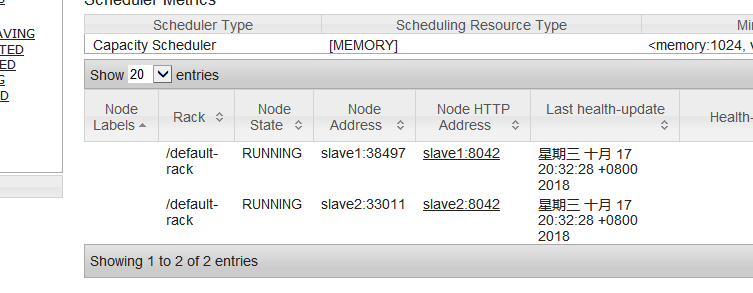
若是如此便启动成功了
至此,简单的hadoop集群版搭建完成了
接下来会进行java代码操作hadoop文件上传下载删除的操作,看之后的blog